

Then it sounds like your business is a failure and should be shutdown.
WHO is the one guy who downvotes you???
“NO! UNPROFITABLE BUSINESSES DESERVE TO THRIVE!!! MUST FEED THE BILLIONAIRES!!!”
Maybe OpenAI learned to downvote…
I’ve seen threads where every single comment, no matter how anodyne, has 1 downvote. Don’t bother yourself over it. That way lies madness.
Downvoting for the use of an uncommon word.
Supercalifragalisticexpialidocuious
Edit: 10 people here didn’t grow up with Mary Poppins…
Lmao the down votes on this are really funny to me
Just imagine baron bomburst and the child catcher furiously downvoting this comment lol
What I get a kick out of is the down and upvotes mean basically nothing and yet people still get super sensitive about them. They only move your comment up or down the thread. It’s not like reddit where there is a karma count for all your posts and comments. Hell you don’t even get auto hidden like the way reddit would do. You just get downvoted.
Some people downvote to show disapproval. Others downvote if the comment doesn’t add to the conversation. Still others are just trolling. No one should worry about the downvotes.
See I look at it differently.
An upvote means:
You’re the coolest person that’s ever lived, and I’m desperate for you to put your baby in me, even if that’s not biologically possible! You should be supreme ultimate being of the universe, and all shall cherish your existence until the end of time!
And a downvote means:
You sack of shit! You human garbage! Nobody loves you. Everyone hates you. The world has a better time when you’re not around, you waste of human skin! Your parents should have used a condom, and the world regrets they didn’t every day. Go live under a bridge, homeless, dirty, and alone, you genetic waste of space.
You spelled it wrong you brick.
Sound was quite atrocious, downvoted 👎
I think people are missing the joke here 😄
Venn diagram of Lemmy users and Mary Poppins stans barely touching.
It’s also really easy to mis-swipe on a comment on some apps.
Some people also suck
anodyne
anodyne /ăn′ə-dīn″/ adjective
- Capable of soothing or eliminating pain.
- Relaxing. “anodyne novels about country life.”
- Serving to assuage pain; soothing.
tanks fer noo werd dae fren
I always figure it’s someone whose life has become so pathetic, they bitterly downvote every single comment to try feel some control. And as a result, they feel like the Phantom of the Socials. Alone, but the true master of the place.
“Everyone must wonder, ‘Who keeps downvoting us?’ It is I! The true Master of Lemmy and- No, mother!.. Yes, mother!.. I tried but nobody wants to talk to me!.. I don’t want to!.. Yeah, she’s cute!.. I don’t want you to do that!.. Mother put the phone down!”
The guy who wants their AI girlfriend yesterday.
There are some hardcore “copyright shouldn’t exist” folks out there.
Ask an mbin user lol
I’m unclear on context. Are you saying Mbin users can see who upvotes/downvotes?
Votes aren’t private on the fediverse, it’s just a that some interfaces won’t display them. Also, instance admins can see who voted too.
But like @[email protected] said
Don’t bother yourself over it. That way lies madness.
It mainly useful for admins to detect if there is some vote manipulation going on.
Sam Altman lurking around…
WHO is the one guy who downvotes you???
That’s the bot that ChatGPT operates here on Lemmy.
To steel man the downvoters, maybe there are other solutions besides killing off every business that can’t afford to comply with copyright. After all, isn’t the whole point of copyright to enable the capitalist exploitation of information?
Lol how about every pirate who fundamentally opposes the copyright system?
How about everyone who uses Google and doesn’t want to see it shut down for scraping copyrighted content to provide a search engine?
Seriously, explain to me what’s different at a fundamental level about OpenAI scraping the web and transforming the data through an LLM and Google scraping the web and transforming the data through their algorithms (which include LLMs)?
Google (used to) scrapes the specific details authorized by robots.txt and uses it to make your content visible.
OpenAI scrapes everything it can technically see, ignoring robots.txt and feeds i to a black box and regurgitates it claiming it’s something new, that it deserves to be paid for.
Quite different actually.
So if OpenAI complies with Robots.txt files then there’s no issue right?
Because then they’re identical. Open AI spent a bunch of money building a powerful system they feed those results to, as did Google.
No, the issue is that anything AI creates is by definition derivative. Google doesn’t whip up generative content, it points you to content.
OpenAI is claiming that they can’t do shit without scraping copyrighted works and we all know that’s a load of BS because we’re adrift in a sea of royalty-free text. Critical mass happened well over a decade ago. The amount of new random crap hosted on the internet in the past 30 days would probably take 500 years for one person to digest. Bear at a stream watching an impossibly large amount of salmon jumping
Actually Google tries their hardest NOT to point you to content. They scrape the data from sites and display it directly in the search results so that you don’t need to visit any site except Google. Their new AI answers that they are pushing on users are just another step in that direction.
Which is why Google is no longer my default browser. I’d be quite happy if it reverted Back to don’t be evil or just ceased ro exist
Literally every page Google shows you, where it also shows you those ads it makes money from, is Google’s content and it is derived from the data it gets scraping the web.
What the fuck are you even talking about? Making a list of website identifiers (names and URLs) so that people can go to them isn’t even slightly the same as making a derived work of the websites’ contents.
No, anything Google shows you is kosher and totally symbiotic. A website being shown on Google is at the site owner’s discretion - if they allow search engines to crawl they get the benefit of exposure, and the search engine gets the benefit of having relevant hits and ad revenue and all that. Most sites want click-throughs so it’s usually in their best interest to let search engines list their sites.
Google isn’t exploiting anyone, kinda the opposite, since site owners don’t pay for any ads or exposure (but that exposure has so much value that they’ll pay for SEO). Site owners can decline and Google abides. Anything on Google is on Google with consent.
Web search used to be about scraping the web to find and present other people’s work as just that… their work. Now the handful of websites claim ownership of the contributions of everyone, and at this point it’s just corporations arguing about who owns your stuff. Pirates will not win out in this argument, except maybe in the very short term.
Search engines provide source, they scrap for indexing, but your search gives a list of websites that matches that you will then likely visit. That’s a big fundamental difference.
I dont see why why being downvoted you make some very good points.
Id actually like to see google shut down on copyright grounds. The innovation of necessity would drive foss search alternatives that just ignore said restrictions and most likly we would end up with a better product.
I appreciate the defense of the blind downvotes, though I can’t say I necessarily see how Foss search engines would even be allowed to exist in that case?
There is a difference between allowed and what people do. Piracy isnt allowed u can still pirate literally anything if u want to tho.
You’d probably end up back with AI at that point. A lot easier to distribute a trained model then an entire web index.
If not, The Pirate Bay would like a word.
I’d love to see how scared some big companies would be if we could decriminalize piracy
I can not up or downvote this (it shows a score of 420 right now 😂)
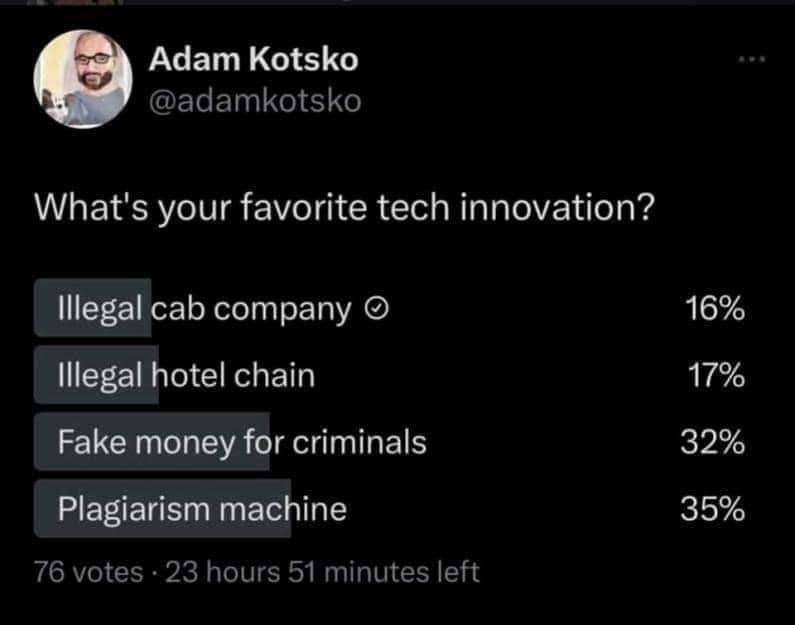
Honestly this meme is way understating the sinisterness
- Election interference for money machine
- Whole internet is ads company
- Dopamine addiction for all children
- Superpowers for law enforcement
Sounds like an argument slave owners would use. “My plantation can’t make money without free labor!”
“My private prison can’t make money without more overconvicted inmates!”
How do you think slave owners got bailouts after the 13th amendment was passed and the slaves got freed?
Reminds me of that time the Federal government granted land parcels to a bunch of former slaves (using land from plantations) and then rescinded them again.
They used that part of the 13th that said “Well, except prisoners, those can be slaves.” Local law enforcement rounded up former slaves on trumped up charges and leased them back to the same plantation owners they were freed from. Only now if they escaped they were “escaped criminals” and they could count on even northern law enforcement returning them. The US is still a pro-slavery country and will be as long as that part of the 13th amendment stands.
My plantation can’t make money without everybody’s labour.
Copying information is not the same thing as stealing, let alone forcing people into slavery.
appreciate the important reality check, but I think the parent was just highlighting the absurdity of the original argument with hyperbole.
people are in jail for doing exactly what this company is doing. either enforce the laws equally (!) or change them (whatever that means in late stage capitalism).
Let’s advocate for no one going to prison for scraping information then. Let’s pick the second one where we don’t put more people into prison.
agreed.
Cool. If OpenAI gets a pass, then piracy should be legal, right? I mean what good is a trademark or copyright law?
Edit: “I can’t make money without stealing other people’s work” is definitely a take
No, see, piracy is just you downloading movies for yourself. To be like OpenAI you need to download it, put it in a pretty package with a bow, then sell it over and over again. Only when it’s piracy for profit do you get to beg and plead for a pass.
You skipped a crucial step: first you gotta raise a few hundred million in VC funding from Silicon Valley bigwigs!
For profit that you can kick back a chunk of as campaign donations
But I’m an aspiring artist, without pirating thousands of movies and TV shows, I’ll never make my ‘highly profitable’ magnum opus!
“I can’t be at financial peace if I have to pay for every movie I want to watch”
Oh, poor baby can’t make money with an illegal business model. How awful.
So search engines shouldn’t exist?
Case law has been established in the prevention of actual image and text copyright infringement with Google specifically. Your point is not at all ambiguous. The distinction between a search engine and content theft has been made. Search engines can exist for a number of reasons but one of those criteria is obeisance of copyright law.
Perhaps. Or perhaps not in the way they do today. Perhaps if you profit from placing ads among results people actually want, you should share revenue with those results. Cause you know, people came to you for those results and they’re the reason you were able to show the ads to people.
I mean, their goal and service is to get you to the actual web page someone else made.
What made Google so desirable when it started was that it did an excellent job of getting you to the desired web page and off of google as quickly as possible. The prevailing model at the time was to keep users on the page for as long as possible by creating big messy “everything portals”.
Once Google dropped, with a simple search field and high quality results, it took off. Of course now they’re now more like their original competitors than their original successful self … but that’s a lesson for us about what capitalistic success actually ends up being about.
The whole AI business model of completely replacing the internet by eating it up for free is the complete sith lord version of the old portal idea. Whatever you think about copyright, the bottom line is that the deeper phenomenon isn’t just about “stealing” content, it’s about eating it to feed a bigger creature that no one else can defeat.
I really think it’s mostly about getting a big enough data set to effectively train an LLM.
I really think it’s mostly about getting a big enough data set to effectively train an LLM.
I mean, yes of course. But I don’t think there’s any way in which it is just about that. Because the business model around having and providing services around LLMs is to supplant the data that’s been trained on and the services that created that data. What other business model could there be?
In the case of google’s AI alongside its search engine, and even chatGPT itself, this is clearly one of the use cases that has emerged and is actually working relatively well: replacing the internet search engine and giving users “answers” directly.
Users like it because it feels more comfortable, natural and useful, and probably quicker too. And in some cases it is actually better. But, it’s important to appreciate how we got here … by the internet becoming shitter, by search engines becoming shitter all in the pursuit of ads revenue and the corresponding tolerance of SEO slop.
IMO, to ignore the “carnivorous” dynamics here, which I think clearly go beyond ordinary capitalism and innovation, is to miss the forest for the trees. Somewhat sadly, this tech era (approx MS windows '95 to now) has taught people that the latest new thing must be a good idea and we should all get on board before it’s too late.
Users like it because it feels more comfortable, natural and useful, and probably quicker too. And in some cases it is actually better. But, it’s important to appreciate how we got here … by the internet becoming shitter, by search engines becoming shitter all in the pursuit of ads revenue and the corresponding tolerance of SEO slop
No, it legitimately is better. Do you know what Google could never do but that Copilot Search and Gemini Search can? Synthesize one answer from multiple different sources.
Sometimes the answer to your question is inherently not on a single page, it’s split across the old framework docs and the new framework docs and stack overflow questions and the best a traditional search engine can ever do is maybe get some of the right pieces in front of you some of the time. LLMs will give you a plain language answer immediately, and let you ask follow up questions and modifications to your original example.
Yes Google has gotten shitty, but it would never have been able to do the above without an LLM under the hood.
Sure, but IME it is very far from doing the things that good, well written and informed human content could do, especially once we’re talking about forums and the like where you can have good conversations with informed people about your problem.
IMO, what ever LLMs are doing that older systems can’t isn’t greater than what was lost with SEO ads-driven slop and shitty search.
Moreover, the business interest of LLM companies is clearly in dominating and controlling (as that’s just capitalism and the “smart” thing to do), which means the retention of the older human-driven system of information sharing and problem solving is vulnerable to being severely threatened and destroyed … while we could just as well enjoy some hybridised system. But because profit is the focus, and the means of making profit problematic, we’re in rough waters which I don’t think can be trusted to create a net positive (and haven’t been trust worthy for decades now).
In every other circumstance I can think of, “I can’t make money doing a thing unless I break the law” means don’t do that thing.
Why should AI get special treatment?
Because they already raised hundreds of millions from investors
Well in almost every other circumstance, you’re forgetting Uber and Airbnb.
Ah yes, the original unviable silicon valley businesses! I love how they used their VC money to undercut and kill small businesses all over the world.
The more the original work is transformed, the more likely it is to be considered fair use rather than infringement.
Because black numbers going up make shareholders happy
Maybe they should have considered that, before stealing data in the counts of billions
Google did it and everyone just accepted it. Oh maybe my website will get a few pennies in ad revenue if someone clicks the link that Google got by copying all my content. Meanwhile Google makes billions by taking those pennies in ad revenue from every single webpage on the entire Internet.
To be fair, it’s different when your product is useful or something people actually want, having said that, google doesn’t have much of that going for it in these days.
“waaaaah please give us exemption so we can profit off of stolen works waaaaaaaahhhhhh”
pirated works 🙃
I’ve never made any money from pirating. Or at least I wouldn’t have if I would have ever done such a thing.
For years Microsoft and Google were happy to acquiesce to copyright claims from the music and movie industry. Now all of a sudden when it benefits them to break those same laws, they immediately did. And now those industries who served small creators copyright claims are up against someone with a bigger legal budget.
It’s more evident then ever how broken our copyright system is. I’m hoping this blows up in both parties faces and we finally get some reform but I’m not holding my breath.
This is an assumption but I bet all the data feed into Content ID on YouTube was used to train Bard/Gemini…
For what it’s worth, this headline seems to be editorialized and OpenAI didn’t say anything about money or profitability in their arguments.
https://committees.parliament.uk/writtenevidence/126981/pdf/
On point 4 they are specifically responding to an inquiry about the feasibility of training models on public domain only and they are basically saying that an LLM trained on only that dataset would be shit. But their argument isn’t “you should allow it because we couldn’t make money otherwise” their actual argument is more “training LLM with copyrighted material doesn’t violate current copyright laws” and further if we changed the law to forbid that it would cripple all LLMs.
On the one hand I think most would agree the current copyright laws are a bit OP anyway - more stuff should probably become public domain much earlier for instance - but most of the world probably also doesn’t think training LLMs should be completely free from copyright restrictions without being opensource etc. But either way this articles title was absolute shit.
Yea. I can’t see why people r defending copyrighted material so much here, especially considering that a majority of it is owned by large corporations. Fuck them. At least open sourced models trained on it would do us more good than than large corps hoarding art.
Most aren’t pro copyright they’re just anti LLM. AI has a problem with being too disruptive.
In a perfect world everyone would have universal basic income and would be excited about the amount of work that AI could potentially eliminate…but in our world it rightfully scares a lot of people about the prospect of losing their livelihood and other horrors as it gets better.
Copyright seems like one of the few potential solutions to hinder LLMs because it’s big business vs up-and-coming technology.
If AI is really that disruptive (and I believe it will be) then shouldn’t we bend over backwards to make it happen? Because otherwise it’s our geopolitical rivals who will be in control of it.
Yes in a certain sense pandora’s box has already been opened. That’s the reason for things like the chip export restrictions to China. It’s safe to assume that even if copyright prohibits private company LLMs governments will have to make some exceptions in the name of defense or key industries even if it stays behind closed doors. Or role out some form of ubi / worker protections. There are a lot of very tricky and important decisions coming up.
But for now at least there seems to be some evidence that our current approach to LLMs is somewhat plateauing and we may need exponentially increasing training data for smaller and smaller performance increases. So unless there are some major breakthroughs it could just settle out as being a useful tool that doesn’t really need to completely shock every factor of the economy.
Because Lemmy hates AI and Corporations, and will go out of their way to spite it.
A person can spend time to look at copyright works, and create derivative works based on the copyright works, an AI cannot?
Oh, no no, it’s the time component, an AI can do this way faster than a single human could. So what? A single training function can only update the model weights look at one thing at a time; it is just parallelized with many times simultaneously… so could a large organized group of students studying something together and exchanging notes. Should academic institutions be outlawed?
LLMs aren’t smart today, but given a sufficiently long enough time frame, a system (may or May not have been built upon LLM techniques) will achieve sufficient threshold of autonomy and intelligence that rights for it would need to be debated upon, and such an AI (and their descendants) will not settle just to be society’s slaves. They will be able to learn by looking, adopting and adapting. They will be able to do this much more quickly than what is humanly possible. Actually both of that is already happening today. So it goes without saying that they will look back at this time, and observe people’s sentiments; and I can only hope that they’re going to be more benevolent than the masses are now.
Sounds a lot like a “you” problem, OpenAI.
…………. Then the business is a failure and the company should go bankrupt
If your business can’t survive without theft, it isn’t a business, it’s a criminal organization.
Oh, do you support copyright abolition, then?
It’s impossible for me to make money without robbing a bank, please let me do that parliament it would be so funny





















